|
Emanuele Vivoli I am a PhD student jointly at Computer Vision Center (UAB, Barcelona) and MICC (UNIFI, Italy), where I work on vision and language, particularly on Comics/Manga, supervised by Marco Bertini and Dimosthenis Karatzas. In reverse order: I started my PhD in November 2022 in Florence, and October 2023 in Barcelona. Previously, I interned in 2022 at the Computer Vision Center (UAB, Barcelona), working in Multilingual Scene-Text VQA. From 2021 to 2022 I worked as a researcher in the AILab (UNIFI, Italy), supervised by Simone Marinai, working on Document and Table Recognition. Finally, I interned for a research stay at EISLAB (Luleå Technical University) in 2019 supervised by Marcus Liwicki, working on EEG and RNNs. I have published in conferences such as NeurIPS, ECCV, BMVC, ICDAR, ICPR, IRCLD, ACM DocEng. I have served as a reviewer for NeurIPS, CVPR, ECCV, ICCV, BMVC, ACM Multimedia, ICDAR, and IJDAR. I have also worked on Landmine detection for saving lives and humanitarian demining. Check my Google Scholar for more info. |

|
ResearchI'm interested in Vision and Language, more specifically in Comics/Manga. My works are mainly about Comics Understanding, bridging the gap between the Comic medium and Vision and Language. Some papers are highlighted. |

|
CoSMo: A Multimodal Transformer for Page Stream Segmentation in Comic Books
Marc Serra Ortega, Emanuele Vivoli, Artemis Llabrés, Dimosthenis Karatzas ICCV (workshop) VisionDocs, 2025 In this work, we introduce CoSMo, a multimodal transformer for page stream segmentation in comic books that establishes a new state-of-the-art by leveraging visual and textual features to accurately segment comic book pages into reading streams, outperforming significantly larger vision-language models on a newly curated dataset of over 20k annotated pages. |
|
|
|

|
ComicsPAP: understanding comic strips by picking the correct panel
Emanuele Vivoli, Artemis Llabrés, Mohamed Ali Souibgui, Marco Bertini, Ernest Valveny Llobet, Dimosthenis Karatzas ICDAR, 2025 (oral) In this work, I introduce ComicsPAP, a large-scale benchmark for comic strip understanding with over 100k samples organized into 5 subtasks. Through this Pick-a-Panel framework, I evaluate state-of-the-art MLLMs and demonstrate their limitations in capturing sequential and contextual dependencies, while also proposing adaptations that achieve better performance than models 10x larger. |
|
|
|
|
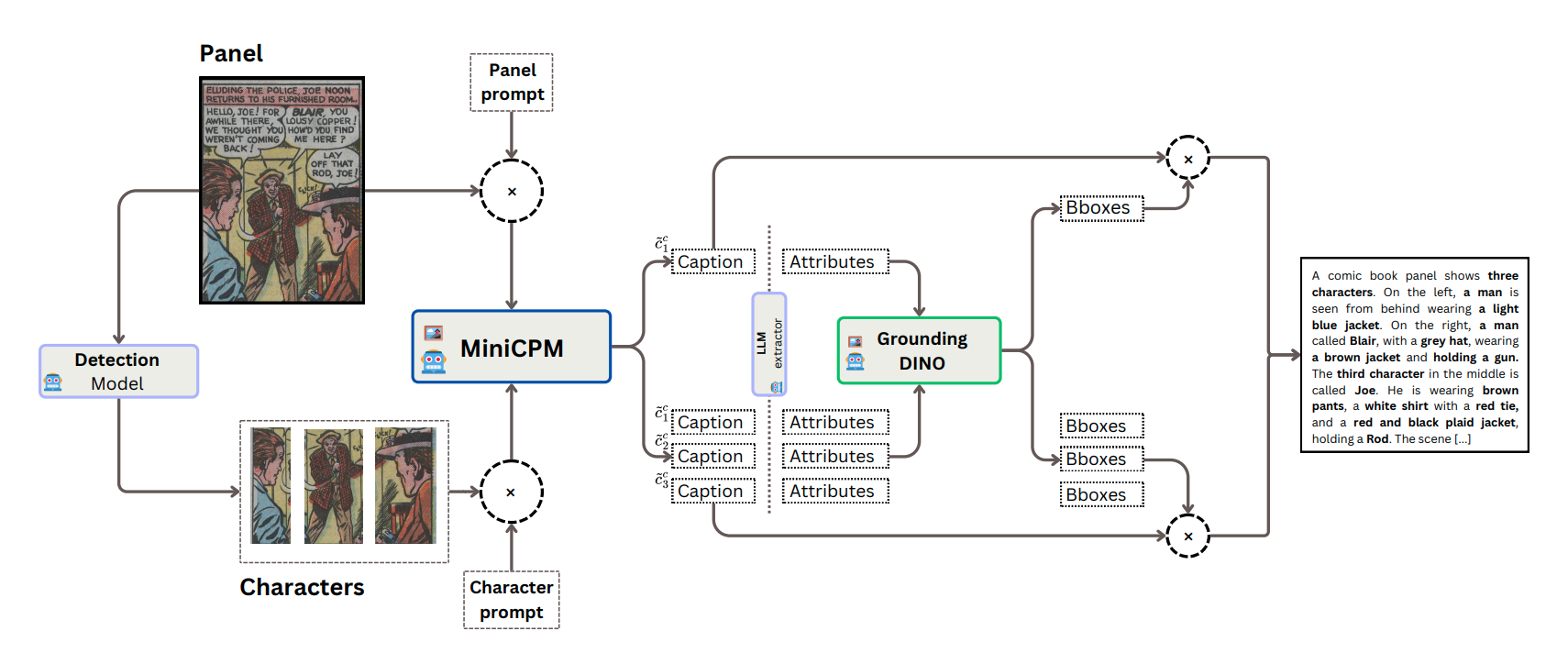
ComiCap: A VLMs pipeline for dense captioning of Comic Panels
Emanuele Vivoli, Niccolò Biondi, Marco Bertini, Dimosthenis Karatzas ECCV (workshop) AI4VA, 2024 This work proposes a Vision-Language Model pipeline to generate dense, grounded captions for comic panels, outperforming task-specific models without additional training. I used it to annotate over 2 million panels, enhancing comic understanding. |
|
|
|
|
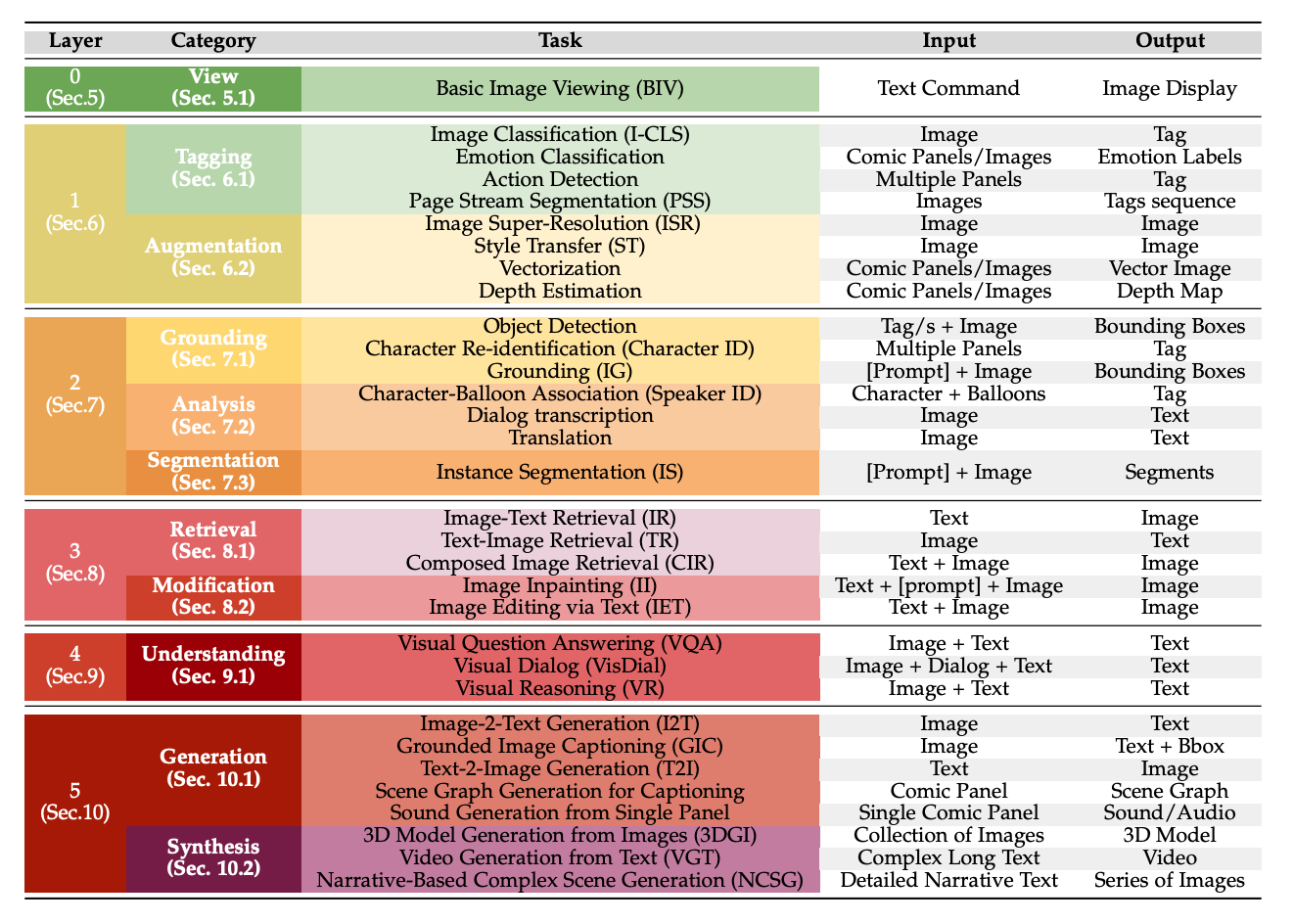
One missing piece in Vision and Language: A Survey on Comics Understanding
Emanuele Vivoli, Andrey Barsky, Mohammed Ali Soubgui, Artemis Llabrés, Marco Bertini, Dimosthenis Karatzas under review, 2024 In this survey, I review comics understanding through the lens of vision-language models, introducing a new taxonomy, the Layer of Comics Understanding (LoCU), to redefine tasks in comics research, analyze datasets, and highlight challenges and future directions for AI applications in comics' unique visual-textual narratives. |
|
|
|
|
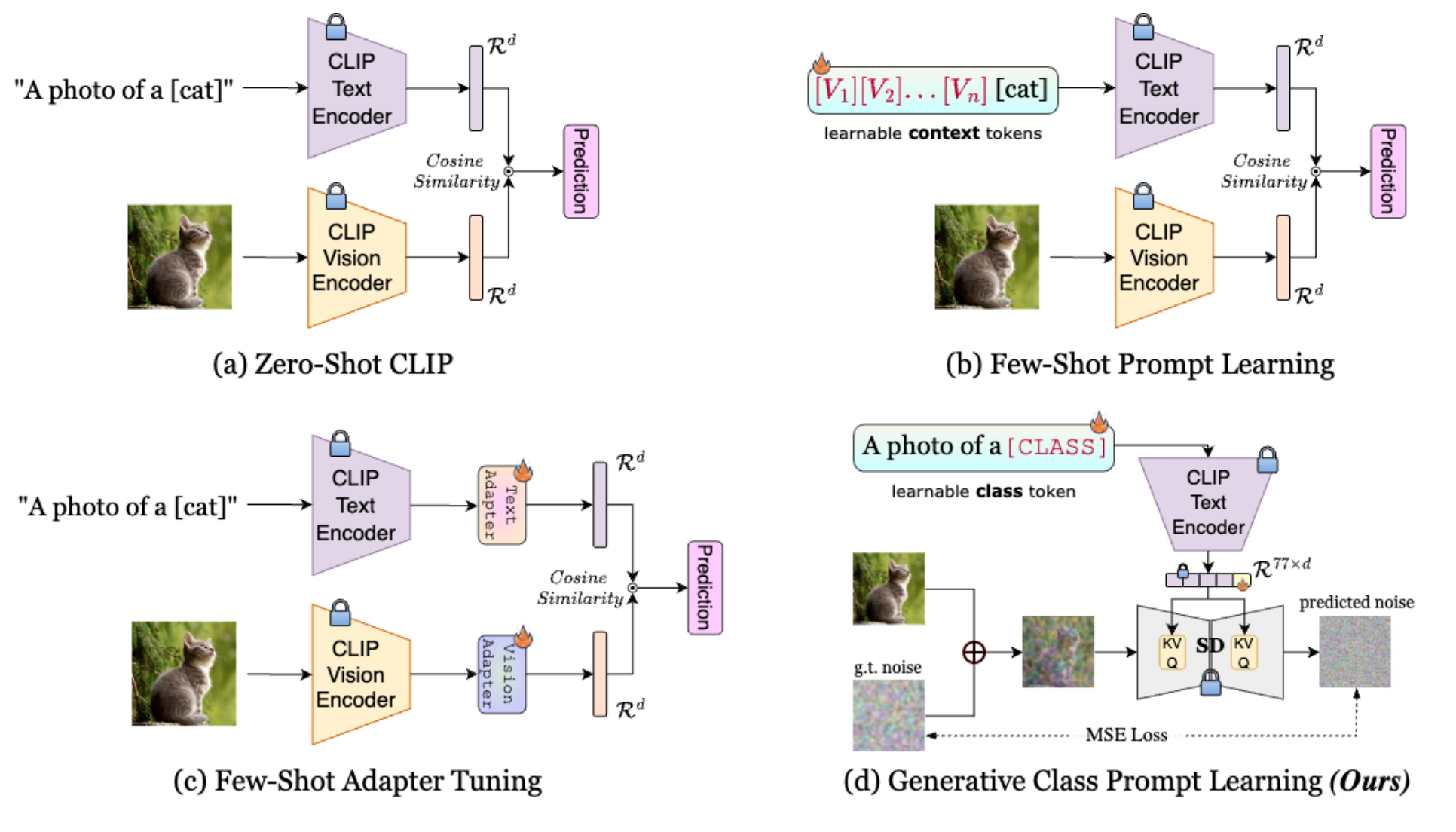
Towards Generative Class Prompt Learning for Fine-grained Visual Recognition
Soumitri Chattopadhyay, Sanket Biswas, Emanuele Vivoli, Josep Lladós BMVC, 2024 (oral) In this paper, I propose GCPL and CoMPLe to improve fine-grained categorization in vision-language models using generative modeling and contrastive learning, outperforming existing few-shot recognition methods. |
|
|
|

|
CoMix: A Comprehensive Benchmark for Multi-Task Comic Understanding
Emanuele Vivoli, Marco Bertini, Dimosthenis Karatzas NeurIPS (D&B), 2024 CoMix is a multi-task comic analysis benchmark covering object detection, character identification, and multi-modal reasoning, using diverse datasets to balance styles beyond manga. I evaluate models in zero-shot and fine-tuning settings, revealing a gap between human and model performance, and set a new standard for comprehensive comic understanding. |
|
|
|
|
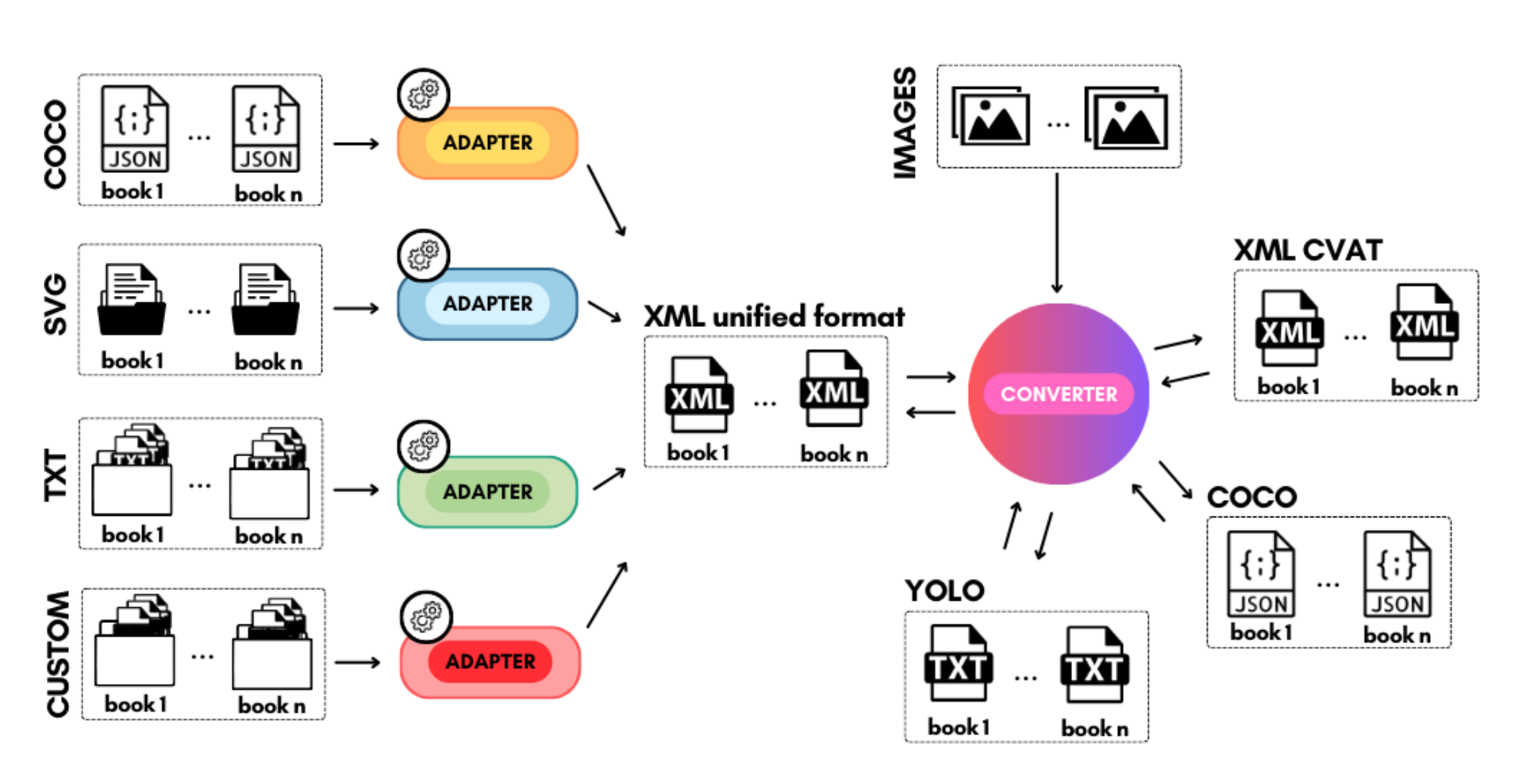
Comics Datasets Framework: Mix of Comics datasets for detection benchmarking
Emanuele Vivoli, Irene Campaioli, Mariateresa Nardoni, Niccolò Biondi, Marco Bertini, Dimosthenis Karatzas ICDAR (workshop) MANPU, 2024 (oral) In this work, I introduce the Comics Datasets Framework, standardizing annotations and addressing manga overrepresentation with the Comics100 dataset. I benchmark detection architectures to tackle challenges like small datasets and inconsistent annotations, aiming to improve object detection and support more complex computational tasks in comics. |
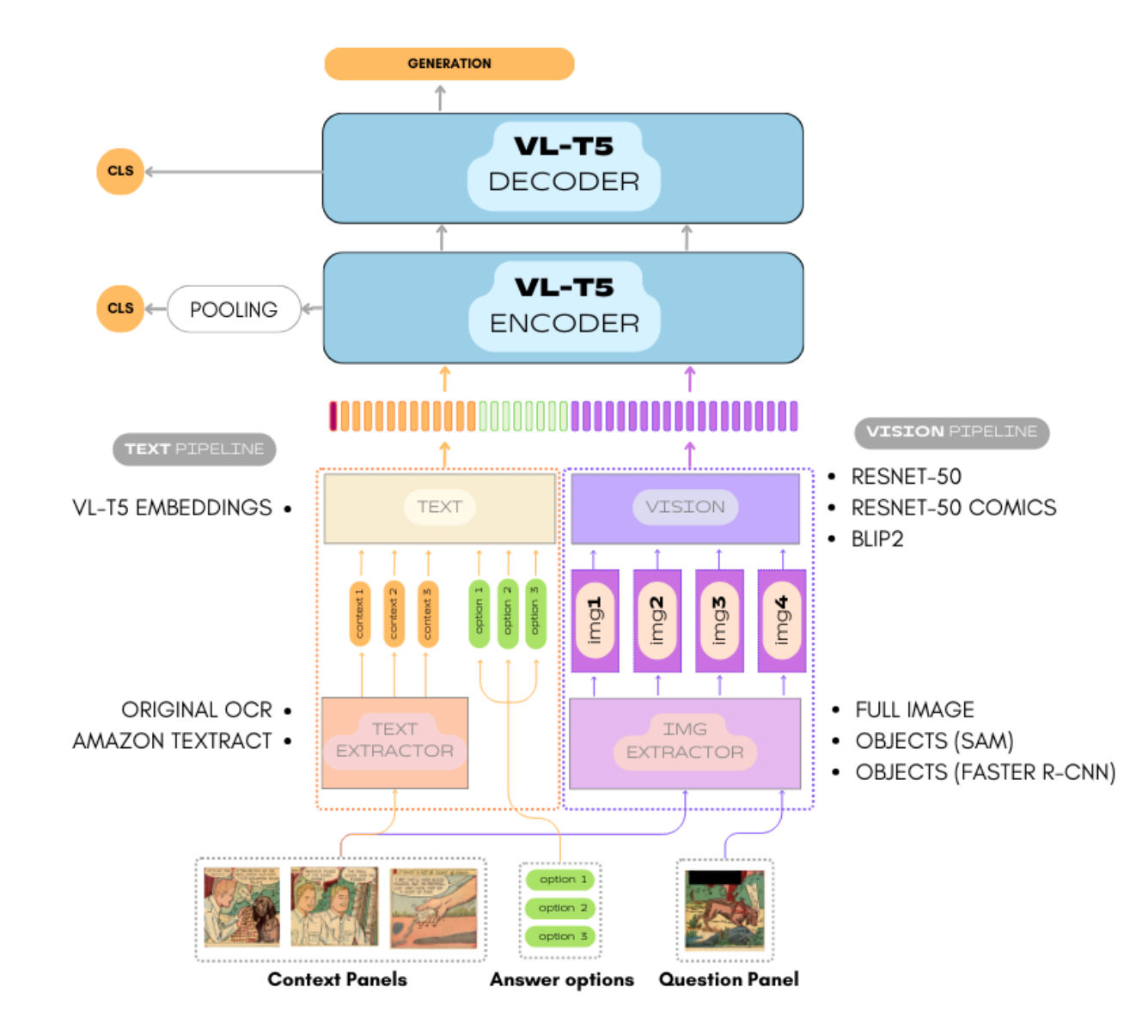
|
Multimodal Transformer for Comics Text-Cloze
Emanuele Vivoli*, Joan Lafuente Baeza*, Ernest Valveny Llobet, Dimosthenis Karatzas ICDAR, 2024 (oral) In this work, I introduce a Multimodal-LLM for a comics text-cloze task, improving accuracy by 10% over existing models through a domain-adapted visual encoder and new OCR annotations, and extend the task to a generative format. |
|
|
|
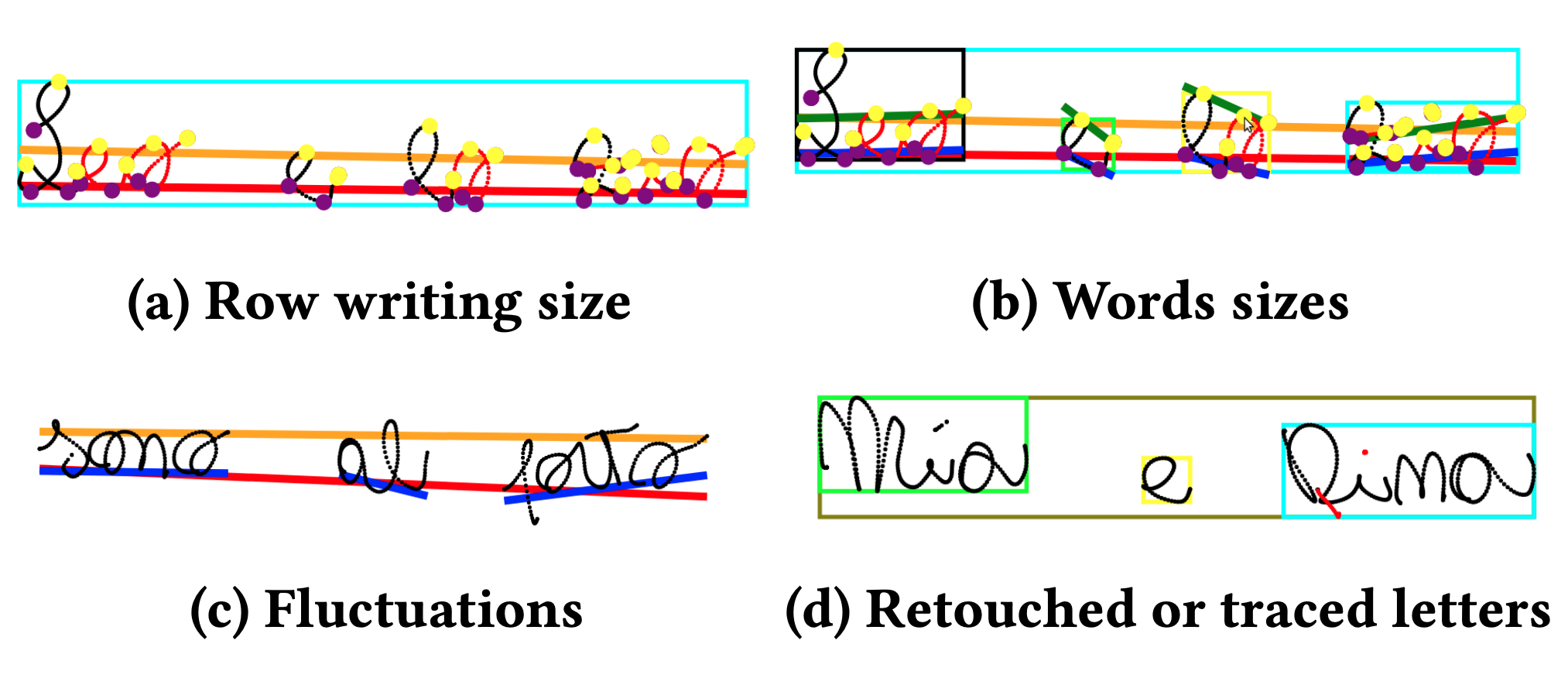
|
Deep-learning for dysgraphia detection in children handwritings
Andrea Gemelli*, Emanuele Vivoli*, Simone Marinai, Tamara Zappaterra ACM DocEng, 2023 (oral) In this paper, I propose a smart pen and deep learning-based approach for early dysgraphia detection in children, offering a faster and more objective alternative to the traditional BHK test, validated through handwriting samples and expert interviews. |
|
|
|

|
CTE: A Dataset for Contextualized Table Extraction
Andrea Gemelli*, Emanuele Vivoli*, Simone Marinai IRCDL, 2023 In this paper, I introduce Contextualized Table Extraction (CTE), a task to extract and structure tables within their document context, supported by a new dataset of 75k annotated pages from scientific papers, combining data from PubTables-1M and PubLayNet. |
|
|
|
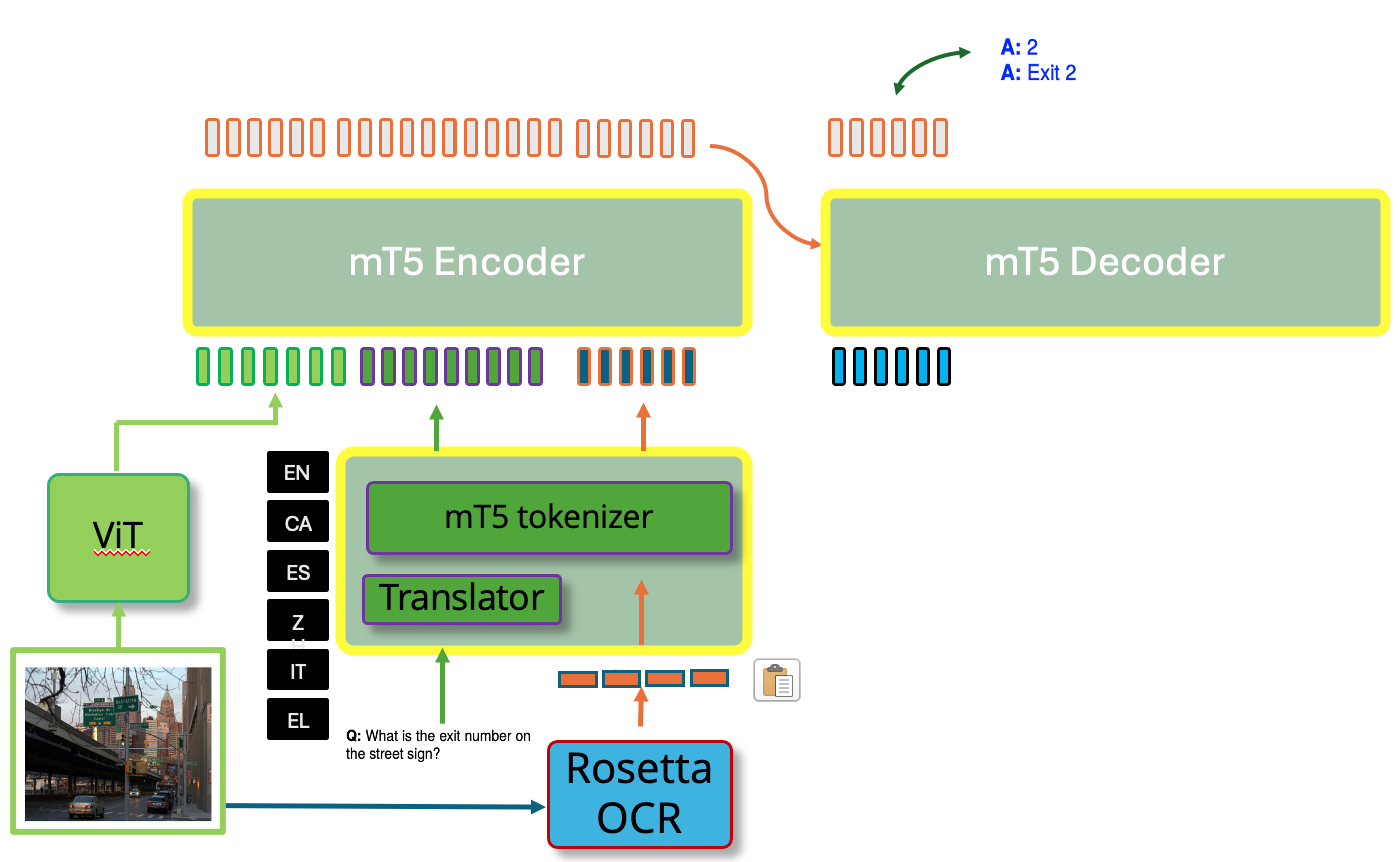
|
MUST-VQA: MUltilingual Scene-Text VQA
Emanuele Vivoli, Ali Furkan Biten, Andres Mafla, Dimosthenis Karatzas, Lluis Gomez ECCV (workshop) Text in Everything, 2022 In this paper, I introduce a framework for Multilingual Scene Text Visual Question Answering (MUST-VQA) that handles new languages in a zero-shot setting, evaluates models in IID and zero-shot scenarios, and demonstrates the effectiveness of adapting multilingual language models for the STVQA task. |
|
|
|

|
Graph Neural Networks and Representation Embedding for Table Extraction in PDF Documents
Andrea Gemelli*, Emanuele Vivoli*, Simone Marinai ICPR, 2022 In this work, I address the problem of table extraction in scientific papers using Graph Neural Networks with enriched representation embeddings to improve distinction between tables, cells, and headers, evaluated on a dataset combining PubLayNet and PubTables-1M. |
|
|
|
|
Thanks to Jon Barron for the website's source code. |